Speech Enhancement
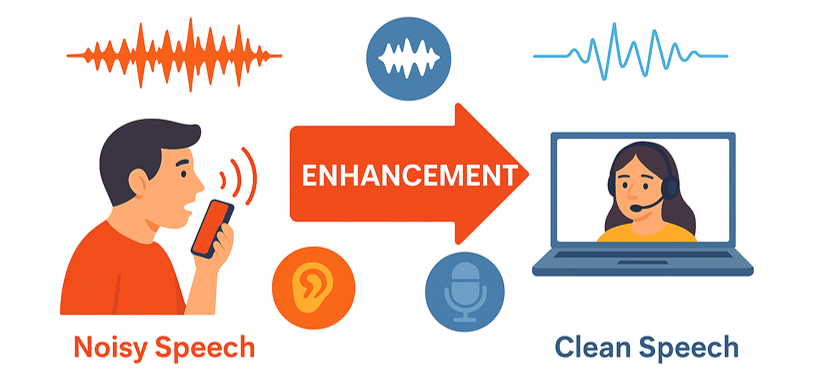
Speech enhancement can be facilitated by deep learning to attenuate background noise, reverberation, and other distortions in audio signals.
Approaches often employ convolutional or transformer-based architectures to achieve low-latency processing.
The objective is to enhance speech intelligibility and perceptual quality for both human listeners and downstream systems.
Transformer-based Speech Enhancement
Transformer-based architectures can demonstrate strong performance in speech enhancement tasks by providing effective noise suppression capabilities.
Text-Guided Speech Enhancement
Speech enhancement techniques that leverage textual information provided by media can achieve superior performance compared to conventional approaches.
Automatic Speech Recognition (ASR)
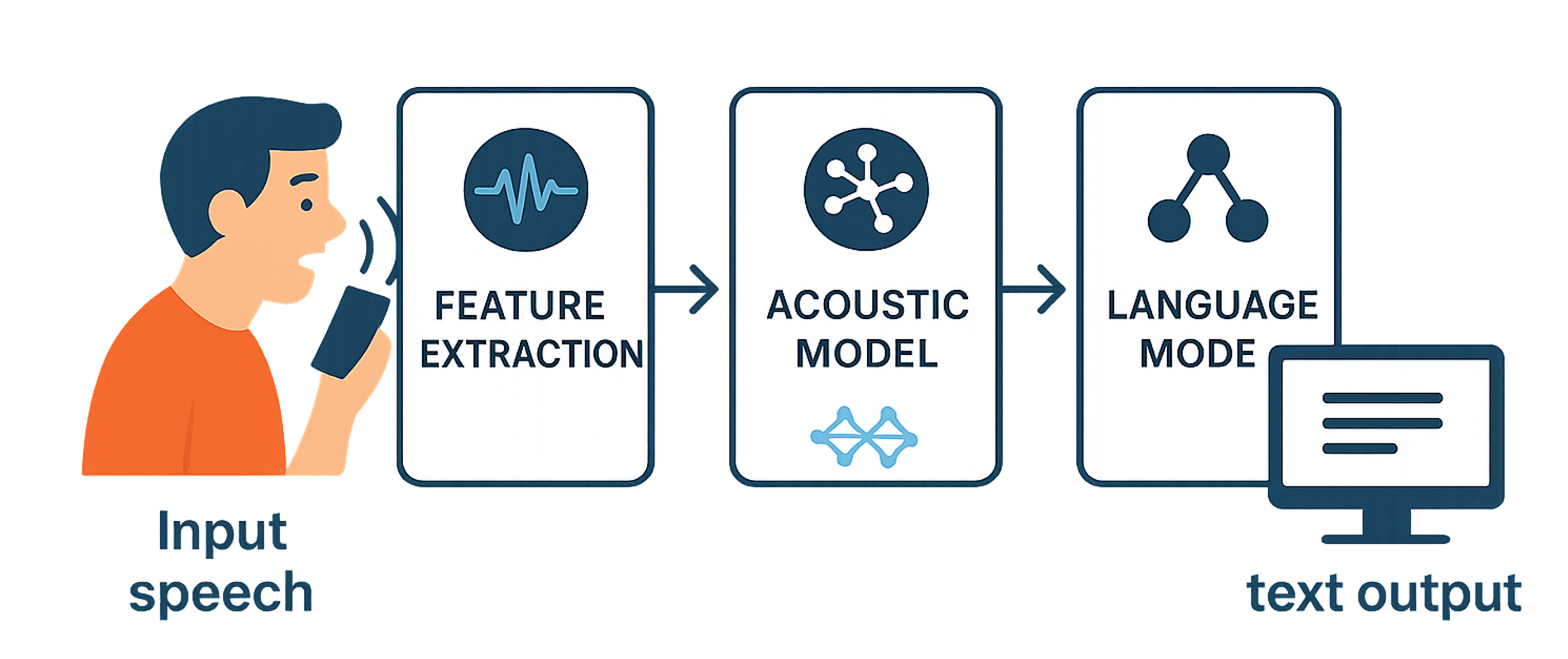
Automatic speech recognition systems can utilize deep neural networks to transcribe spoken language into text.
State-of-the-art approaches frequently utilize transformer-based or end-to-end acoustic-linguistic architectures which can be further enhanced with noise-robust training strategies.
These systems are designed to generalize across languages, accents, and diverse acoustic environments, including adverse and noisy conditions.
Real-Time Speech-to-Text
Real-time speech recognition can provide users with transcriptions on the fly by leveraging low-computation architectures and maintaining contextual information.
Noise-Robust Speech Recognition System
Ambient noise can degrade the performance of speech recognition, and dedicated noise reduction techniques may be employed to enhance system robustness.
Language Modeling
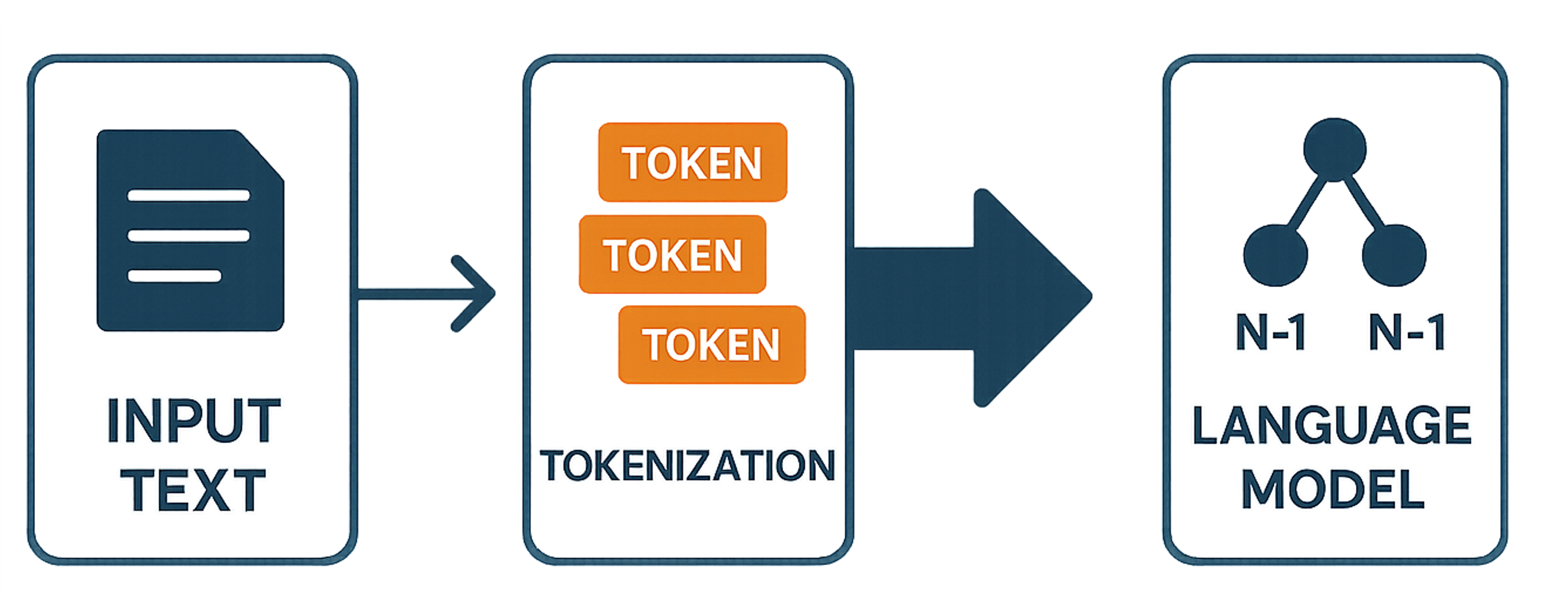
Language modeling involves predicting or generating sequences of text by capturing statistical and contextual dependencies.
Transformer-based models, such as BERT and GPT, are commonly adopted for these purposes.
Such models provide the foundation for tasks ranging from dialogue systems to multimodal understanding.
Real-Time Machine Translation
Real-time machine translation can deliver translated text to users instantaneously by utilizing low-computation models while preserving contextual information.
AI-Generated Text Detection
By analyzing the contextual characteristics of a given text, it is possible to determine whether the text was generated by a language model or authored by a human.
Acoustic Scene Detection
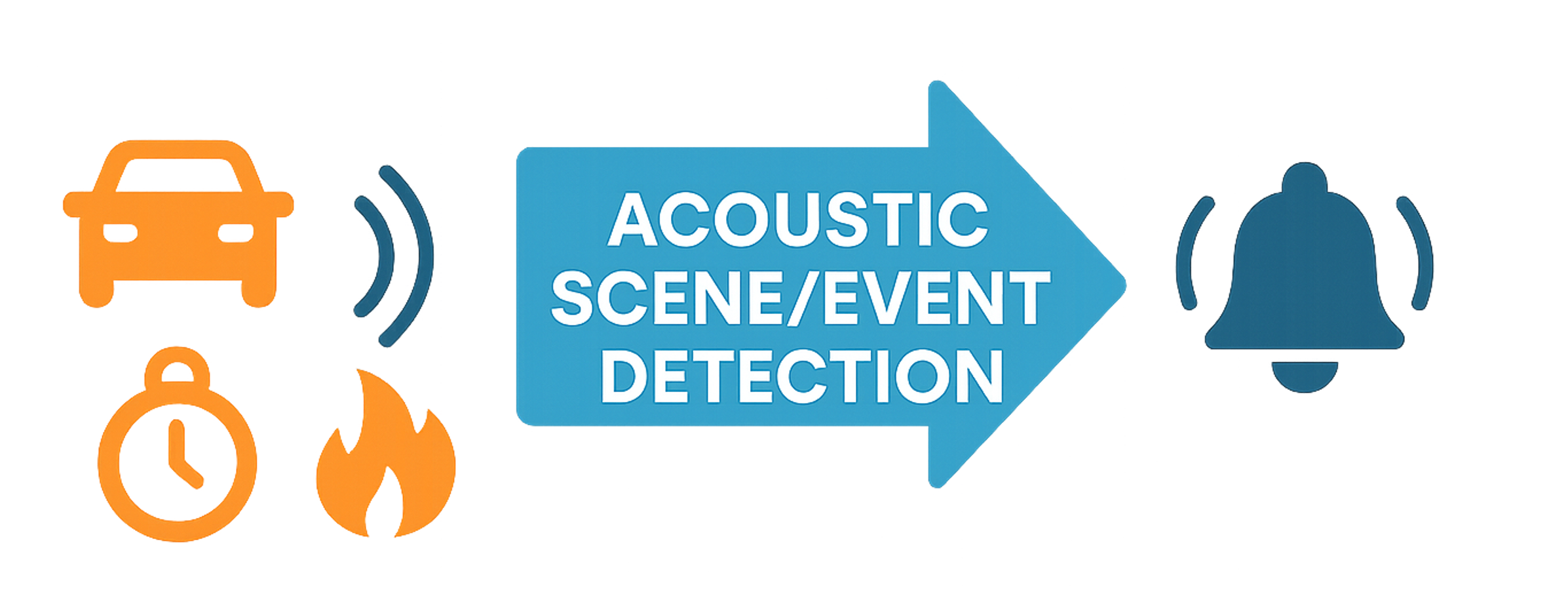
Acoustic scene detection involves identifying and classifying the sounds present in a given audio environment by capturing spatial and temporal characteristics.
Deep learning models, particularly convolutional neural networks (CNNs), are commonly employed for these tasks.
Such models enable applications ranging from surveillance to smart home systems.
Low-Complexity Acoustic Scene Classification
Low-complexity acoustic scene classification can be achieved by utilizing lightweight models that maintain performance while reducing computational requirements.
3D-Audio
3D audio reproduction can be realized by modeling spatial cues such as directionality, distance, and environmental reflections.
Data-driven methods, including deep learning, are often applied for binaural rendering and sound field reconstruction.
This technology enables immersive auditory experiences in applications such as virtual and augmented reality.
Personalized HRTF
Personalized head-related transfer functions (HRTFs) are utilized to emulate the unique characteristics of an individual's auditory system, thereby facilitating accurate spatial sound perception.